Apresentação do problema
Uma das principais dificuldades encontradas pelos desenvolvedores de aplicações orientadas a objeto é a persistência dos dados. Em muitos casos opta-se por utilizar bancos relacionais e, com isso, surge o problema de mapear os objetos para o banco.
As soluções geralmente adotadas envolvem descrever uma relação entre as propriedades do objeto e os campos de uma ou mais tabelas no banco relacional. Essa relação pode ser descrita através de queries SQL, em que a aplicação é responsável por persistir e recuperar os objetos direto no banco, ou através de ferramentas mais sofisticadas como o Prevayler, Hibernate, ou mesmo Enterprise Java Beans.
Quando o desenvolvedor opta por fazer a persistência "manualmente" usando queries, perde-se muito tempo desenvolvendo código para recuperar e salvar os dados em banco e a aplicação fica muito vulnerável a pequenos erros de programação típicos de trabalhos repetitivos e copy-and-paste.
A maioria das ferramentas existente para resolver esse problema requer que o usuário descreva o mapeamento OO-Relacional, por exemplo em XML, implemente interfaces e obedeça a uma série de restrições. Para projetos grandes, algumas delas são muito boas porém, para aplicações menores acabam introduzindo muita complexidade.
Objetivos
O objetivo desse projeto é construir um arcabouço de simples utilização que facilite o trabalho do desenvolvedor, tornando o processo de persistir dados o mais transparente possível e sem onerar excessivamente os recursos da máquina.
O público alvo do Canguru é o desenvolvedor de aplicações que não necessita ou não queira toda a complexidade de um sistema como, por exemplo, o Hibernate.
Para tal, o Canguru deve apresentar as seguintes características:
- Simplicidade: essa deve ser a característica fundamental do arcabouço.
- Isolar o desenvolvedor da utilização do banco de dados; as únicas informações que o desenvolvedor precisa ter sobre o banco são os dados de conexão.
- Abolir mapeamentos: o sistema deve ser capaz de funcionar sem exigir do usuário informações sobre mapeamento OO-Relacional.
- API simples: a interface de utilização deve ser simples, utilizando preferencialmente extensões de interfaces já bem conhecidas de programadores java como o Set e a Collection.
- Manter apenas os objetos necessários em memória, possibilitando manipular um grande volume de dados. Vale atentar para o fato de que este objetivo ainda não foi alcançado.
- Recuperar seletivamente os dados utilizando comparações com os valores de suas propriedades. Algo equivalente a um SELECT ... WHERE ... em banco relacional.
- O resultado do projeto deve também ser uma ferramenta aplicável ao desenvolvimento de solucões reais em java, e não apenas um estudo acadêmico.
Solução
O Canguru é um arcabouço em Java para persistência e recuperação de dados, que se baseia em uma forma transparente de fazer a conversão entre Objetos de aplicações Java e registros salvos no banco de dados, oferecendo uma interface simples derivada de java.util.Set com métodos adicionais para salvar, recuperar e fazer busca por objetos.
Utilizando o Canguru
Para utilizar o Canguru, o desenvolvedor tem apenas dois contatos com o banco de dados: a criação da base (somente da base) e do arquivo de configuração do Canguru como abaixo.
database.prp:
#Configurações para conexão com o banco de dados
driver=org.postgresql.Driver
url=jdbc:postgresql://127.0.0.1:5432/databasename
user=usuario
password=senha
Nesse arquivo são informados os dados para a conexão com o banco de dados:
- driver: driver para conexão JDBC. No exemplo estamos utilizando um driver para conexão com o Postgres
- url: string com formato definido pelo driver utilizado. Geralmente possui nome do driver, nome da base de dados a ser utilizada, endereço e porta de acesso ao banco
- user: nome do usuário da base de dados
- password: senha do usuário
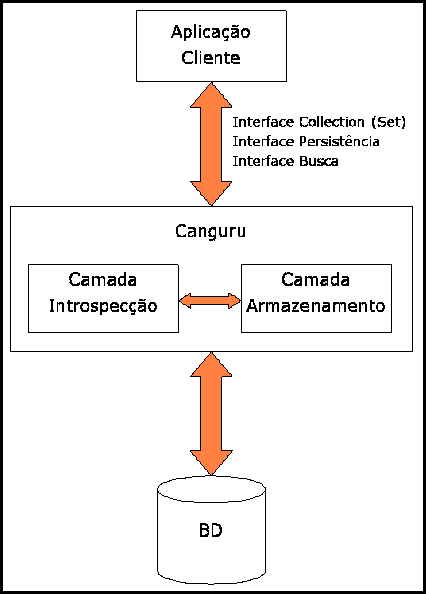
Com a conexão para o banco configurada, a aplicação cliente deve instanciar um objeto da classe Canguru, informando qual o tipo (classe ou interface) dos objetos que serão armazenados. Pode-se utilizar diversos cangurus para armazenar objetos de tipos diferentes. A partir disso, as funcionalidades do arcabouço são acessadas através de três interfaces (fig. 1) disponibilizadas na classe Canguru:
- Collection (Set): A classe Canguru implementa a interface java.util.Set, oferencendo uma interface simples e conhecida para que a aplicação armazene e manipule os objetos que devem ser persistidos.
- Persistência: A interface de persistência oferece métodos para salvar os objetos armazenados em um Canguru no banco de dados e para fazer a operação inversa: recuperar registros do banco de dados, inserido-os como objetos no Canguru
- Busca: Essa interface oferece métodos para fazer uma recuperação seletiva de objetos através de filtros em seus atributos.
Dessa forma, a aplicação consegue inserir elementos em uma Collection (Canguru), solicitar que sejam salvos em banco quando necessário e recuperá-los total ou parcialmente, através de filtros.
Para detalhar a utilização do Canguru, vamos usar o exemplo abaixo:
CanguruExample.java:
1: import java.sql.SQLException; 2: import java.util.Iterator; 3: import java.util.Set; 4: import canguru.Canguru; 5: import canguru.MixurucaEnhanced; 6: import canguru.descriptor.exception.AttributeDefinitionNotFoundException; 7: import canguru.descriptor.exception.InvalidAttributeException; 8: import canguru.descriptor.exception.InvalidNameException; 9: import canguru.exception.BeanManipulationException; 10: import canguru.exception.CanguruInitializationException; 11: import canguru.exception.FilterException; 13: /** 14: * Pequeno exemplo de uso do Canguru. 15: */ 16: public class CanguruExample { 18: CanguruExample() { 19: } 21: public void run() { 23: try { 24: // inicializa o canguru, os parâmetros são: 25: // um String que servirá como identificador para essa coleção 26: // um Class que indica qual a classe dos objetos que o canguru deverá aceitar 27: Canguru canguru = new Canguru("exemplo", MixurucaEnhanced.class); 29: // cria alguns objetos para serem adicionados (da mesma classe que foi passada 30: // para o construtor do Canguru) 31: MixurucaEnhanced mixuruca1; 32: MixurucaEnhanced mixuruca2; 33: MixurucaEnhanced mixuruca3; 35: //atribui valores a algumas das propriedades dos objetos criados 36: mixuruca1 = new MixurucaEnhanced(); 37: mixuruca1.setStringTest("teste"); 39: mixuruca2 = new MixurucaEnhanced(); 40: mixuruca2.setStringTest("teste"); 41: mixuruca2.setAInteger(new Integer(42)); 43: mixuruca3 = new MixurucaEnhanced(); 44: mixuruca3.setAInteger(new Integer(42)); 46: // adiciona os objetos ao Canguru 47: canguru.add(mixuruca1); 48: canguru.add(mixuruca2); 49: canguru.add(mixuruca3); 50: canguru.add(new MixurucaEnhanced()); 52: try { 53: //salva os dados 54: canguru.save(); 55: } 56: catch (ClassNotFoundException e1) { 57: e1.printStackTrace(); 58: } 59: catch (SQLException e1) { 60: e1.printStackTrace(); 61: } 62: catch (java.io.IOException e1) { 63: e1.printStackTrace(); 64: } 65: catch (canguru.exception.IOException e1) { 66: e1.printStackTrace(); 67: } 68: } 69: catch (CanguruInitializationException e) { 70: //a inicialização do canguru falhou 71: e.printStackTrace(); 72: } 74: //recuperando os dados 75: try { 76: //inicializa um novo canguru utilizando o mesmo string como identificador e o mesmo class, 77: // assim poderemos recuperar os dados salvos pela outra instância do Canguru. 78: Canguru canguru = new Canguru("exemplo", MixurucaEnhanced.class); 80: try { 81: //recupera todos os objetos objetos salvos em banco 82: canguru.restore(); 84: //percorre os elementos 85: Iterator it = canguru.iterator(); 86: while (it.hasNext()) { 87: System.out.println(it.next()); 88: } 90: try { 91: // busca elementos especificos 92: canguru.addFilter("stringTest", "teste"); 93: Set filtered = canguru.getFilteredSubset(); 94: //nesse ponto o filtered possui referencia para os dois objetos que possuem 95: //a propriedade stringTest == teste 97: //restringindo mais a busca 98: canguru.addFilter("AInteger", new Integer(42)); 99: filtered = canguru.getFilteredSubset(); 100: //agora o filtered soh possui referencia para um objeto que possui stringTest == test 101: //e AInteger == 42 103: //limpa os filtros 104: canguru.resetFilter(); 105: //adiciona outro filtro 106: canguru.addFilter("AInteger", new Integer(42)); 107: filtered = canguru.getFilteredSubset(); 108: //agora o filtered possui referencia para dois objetos com AInteger == 42 110: } 111: catch (AttributeDefinitionNotFoundException e2) { 112: e2.printStackTrace(); 113: } 114: catch (InvalidNameException e2) { 115: e2.printStackTrace(); 116: } 117: catch (InvalidAttributeException e2) { 118: e2.printStackTrace(); 119: } 120: catch (FilterException e2) { 121: e2.printStackTrace(); 122: } 124: } 125: catch (java.io.IOException e1) { 126: e1.printStackTrace(); 127: } 128: catch (ClassNotFoundException e1) { 129: e1.printStackTrace(); 130: } 131: catch (SQLException e1) { 132: e1.printStackTrace(); 133: } 134: catch (BeanManipulationException e1) { 135: e1.printStackTrace(); 136: } 137: } 138: catch (CanguruInitializationException e) { 139: e.printStackTrace(); 140: } 141: } 143: public static void main(String[] args) { 144: new CanguruExample().run(); 145: } 146: }
Na linha 27 inicializamos uma instância do Canguru passando como parâmetros um string
exemplo e uma classe MixurucaEnhanced.class. O string tem a função de identificador para a coleção, a classe
indica qual o tipo dos objetos que essa instância deverá aceitar. Cada instância pode trabalhar apenas com um tipo de objeto.
Entre as linhas 29 e 44 criamos algumas instâncias de objetos da classe
MixurucaEnhanced e atribuímos valores a algumas de suas propriedades. A seguir adicionamos esses objetos ao Canguru
(linha 47).
Para salvar todos os objetos em banco usamos canguru.save() na linha 54 e ao executar esse
método o Canguru irá criar automaticamente as tabelas necessárias.
A próxima etapa é recuperar os dados, para fazê-lo vamos utilizar uma nova instância do Canguru, que deve ser inicializada (linha 78) com os mesmos parâmetros da instância que usamos para salvar. Repare que não estamos usando a instância anterior apenas para ilustrar. É perfeitamente possível carregar os dados do banco na mesma instância que foi usada para salvá-los.
Após inicializado o Canguru, para recuperar os dados, basta chamar o método canguru.restore() (linha 82), para percorrer os objetos recuperados usamos os métodos disponíveis em java.util.Set, conforme ilustrado na linha 85. Adicionalmente dispomos de um sistema de filtros que permite buscar objetos pelos valores de suas
propriedades (linhas 92 a 107).
Arquitetura
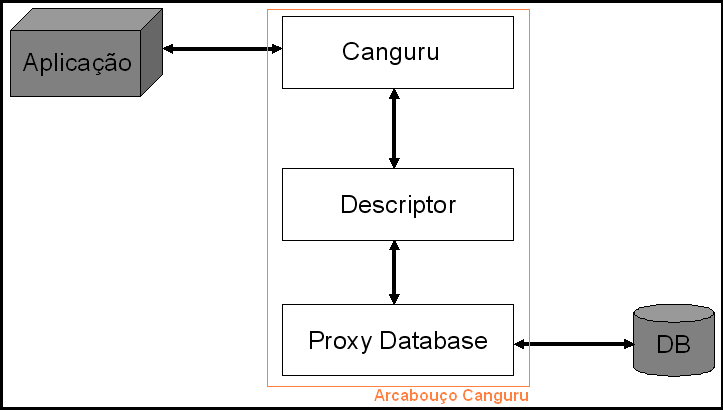
O Arcabouço Canguru é dividido em três módulos (fig. 2):
- Canguru: É o módulo acessado pela aplicação cliente. Armazena os objetos a serem persistidos ou recuperados e faz o tratamento de introspecção para análise das propriedades deles.
- Descriptor: Camada intermediária entre o módulo Canguru e o Proxy para operações com o banco de dados. É responsável pela conversão entre tipos Java e tipos do banco de dados.
- Proxy Database: Realiza as operações de banco de dados através de queries baseadas nas definições descritas pelo módulo Descriptor.
Para obter informações detalhadas sobre esse módulo, consulte a API do arcabouço Canguru.
Canguru
O Canguru possui duas classes mais importantes: Canguru e CanguruSaver, a primeira é a interface
que o desenvolvedor usa, a segunda é a classe que trata os objetos para salvá-los e recuperá-los.
Quando o método save() é chamado o Canguru passa a
Collection com os objetos para o CanguruSaver, que por sua vez os percorre como um grafo, utilizando o java.beans.Intrsopector para fazer uma
espécie de numeração topológica, atribuindo ids e detectando ciclos.
Para atribuir ids utilizamos o PMap que é um Map java que usa "==" no
lugar de .equals() para fazer as comparações. Algum tempo depois de termos feito essa implementação encontramos o artigo
Long-Term Persistence for JavaBeans de MILNE,
Philip e WALRATH, Kathy que sugere uma implementação semelhante.
Uma vez percorridos e devidamente identificados (por ids) os objetos são analisados e os valores e ids de
suas propriedades são salvos dentro de um Descriptor juntamente com
sua forma serializada.
Para recuperar os objetos o CanguruSaver os deserializa do banco, guardando cada uma de suas propriedades e o
próprio objeto em um PMap (na realidade é usado um ObjectTable, que facilita o uso do PMap), assim o Canguru pode identificar propriedades que referenciem
uma mesma instância, e "corrigir os ponteiro".
Os filtros são pares (atributo, valor) enviados para o Descriptor que os usa como critério de seleção na
busca no banco.
É importante ressaltar que o tratamento de referências só é feito no objeto que é passado diretamente como parâmetro para
o método add(Object o) do Canguru, isso irá causar problemas ao salvar grafos mais complexos de objetos.
Descriptor
O Módulo Descriptor é responsável por receber as solicitações de persistência, recuperação e busca do Canguru e repassá-las para o Proxy Database de forma adequada. A classe Descriptor serve como fachada para todo o pacote e é a única classe que pode ser acessada pelos outros módulos.
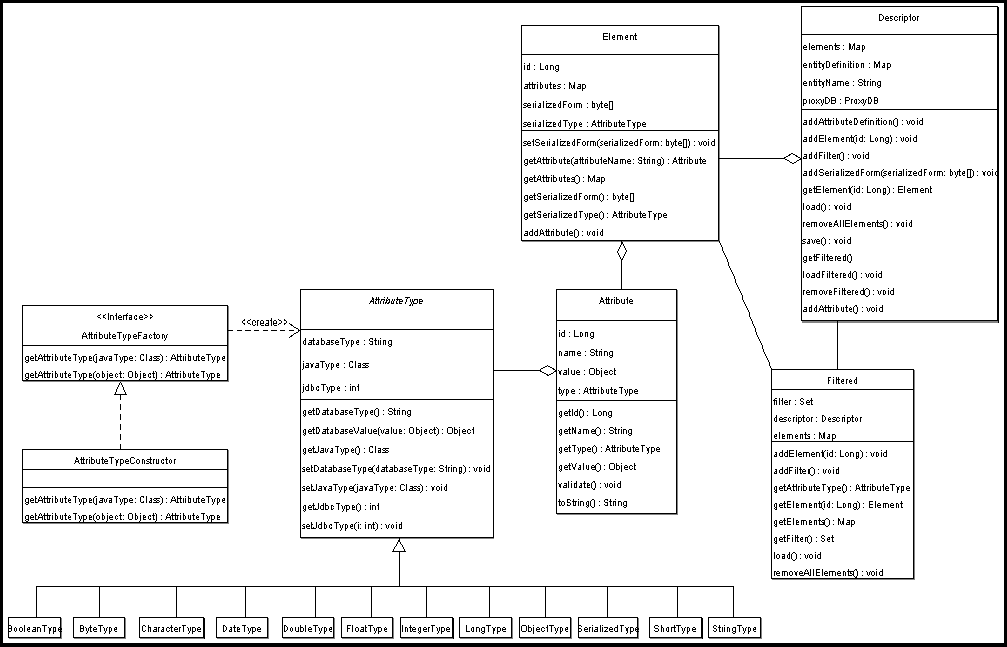
Para o entendimento desse módulo são necessárias três definições:
- Element: Um elemento representa um objeto na aplicação cliente e a sua conversão em um registro na tabela criada no banco de dados. Cada elemento armazena a sua forma serializada, que é fornecida pelo módulo Canguru ou recuperada do banco de dados. Possui também um mapa com seus atributos na forma (nome_atributo, valor) também definidos pelo Canguru através da introspecção realizada.
- Attribute: Representa um atributo de um objeto na aplicação cliente e a sua conversão em um ou mais campos na tabela do banco de dados. Cada atributo possui um Attribute Type (definido abaixo), nome, id e valor. O nome indica a coluna na tabela à qual o atributo se refere. O id é utilizado para atributos que devam ter suas referências recuperadas (tipos não "primitivos"). O valor é preenchido para atributos que possam ser utilizados para busca (tipos "primitivos"). Um atributo pode ser adicionado pelo Canguru ou recuperado do banco de dados.
- Attribute Type: A finalidade do Tipo do Atributo é definir a conversão entre um atributo na aplicação java e a sua representação no banco de dados através de uma ou mais colunas. Ele é construído através de uma fábrica (ver Diagrama de Classes), que decide, através do tipo Java do atributo, qual a especialização adequada de Attribute Type a ser utilizada para aquele atributo.
Quando um Canguru é criado, ele instancía o descriptor que utilizará, e o configura para realizar suas operações de persistência, recuperação e busca.
São definidos:
- entityName: utilizado para definir o nome da tabela a ser criada/utilizada no banco de dados.
- entityDefinition: mapa no formato (nome, tipo do atributo). O Canguru, através de introspecção no tipo que irá armazenar, coleta os atributos a serem persistidos e os insere na definição Descriptor.
A partir do momento em que o Descriptor está configurado, são oferecidos três conjuntos de operações ao Canguru. O Canguru pode adicionar os elementos a serem persistidos e solicitar que sejam salvos no banco de dados. Pode solicitar que o Descriptor carregue os elementos a partir do banco do dados para depois carregá-los para a aplicação. Ou ainda, pode inserir filtros de busca, fazer a pesquisa e recuperar os elementos retornados. Todas essas operações são, por sua vez, delegadas ao Proxy Database associado ao Descriptor.
Proxy Database
Na camada de proxy para o banco de dados são realizadas todas as operações de banco delegadas pelo descriptor. Para realizar essas operações, o proxy utiliza as configurações definidas no descriptor associado. Além da conexão com o banco de dados, as seguintes operações são realizadas:
- save: Verifica a existência da tabela no banco, criando-a caso necessário, e varre elementos do descriptor associado para salvá-los na tabela
- load: Carrega elementos do banco de dados e os insere no descriptor associado ao proxy, sobrescrevendo dados anteriores
- loadFiltered: Carrega elementos do banco de dados de acordo com filtros definidos no descriptor associado ao proxy.
Ferramentas, técnicas e padrões utilizados
Como decidimos trabalhar separadamente, cada um em sua casa, precisamos de ferramentas tanto para integração do código em si, como para integração da equipe, permitindo discussões sobre as soluções encontradas, definição de próximos passos e divisão de tarefas. Para o controle de versões de código utilizamos o CVS, que permite manter o código sincronizando e íntegro, mesmo com alterações concorrentes de vários programadores. Para solucionar os problemas de comunicação, criamos uma lista de discussão, um WiKi e utilizamos massivamente o telefone.
Para programar, utilizamos o Eclipse, que oferece uma série de recursos interessantes, entre eles padronização de código, geração automática do esqueleto para Javadoc e os métodos mais comuns de refatoração de código. Utilizamos também o JUnit integrado ao Eclipse para realizar os testes de Unidade da aplicação.
O arcabouço Canguru foi desenvolvido utilizando o J2SE 1.4.2 e foi testado para o SGBD Postgres 7.3
No desenvolvimento utilizamos, ainda, alguns padrões de projeto. Para instanciar a subclasse adequada do Tipo de Atributo utilizamos o padrão Factory e procuramos utilizar Façades entre os subsistemas da aplicação.
Restrições
- O Canguru recupera as referências dos objetos só no primeiro nível, ver Arquitetura, Canguru.
- A solução só foi testada em conjunto com o banco de dados PostgreSQL 7.3, podem ser necessárias pequenas modificações no código do Canguru para suportar outros bancos.
- O sistema de filtros ainda não suporta buscas por padrões ou máscaras. Em breve o uso de expressões regulares será implementado para superar essa limitação.
- A busca é feita unindo os critérios do filtro pelo operador lógico
AND, não sendo possível fazer buscas por objetos que possuam a propriedade xxxx="valor1" ou xxxx="valor2". - Ao recuperar os objetos do banco, todo o Set é carregado em memória. Máquinas com pouca memória terão problemas para trabalhar com quantidades grandes de objetos. Talvez a utilização de proxies de acesso aos objetos possa minimizar esse problema.
- Essa é uma implementação inicial do Canguru, e como tal o código ainda não está bem otimizado tanto em consumo de memória como em performance.
Organização da equipe e metodologia de desenvolvimento
A equipe é composta por Felipe Gustavo de Almeida, Fernanda Simões de Almeida e Maíra de Assis Ramos.
Os estudos iniciais sobre o projeto, como introspecção, ferramentas relacionadas ao assunto, ferramentas que poderiam auxiliar o projeto, foram feitos individualmente e, posteriormente, discutidos com toda a equipe.
Já toda a fase de modelagem foi marcada por reuniões da equipe toda para discutir e definir as diretrizes a serem tomadas. Assim que conseguimos uma modelagem mais precisa do projeto, pudemos fazer uma divisão inicial das tarefas entre os componentes do grupo, sendo cada integrante responsável por determinadas atividades que poderiam ser realizadas separadamente. Entretanto, toda solução encontrada foi discutida na busca de aprimoramentos ou novas idéias, assim como a própria divisão de tarefas e objetivos foram rediscutidos e adaptados ao logo do desenvolvimento.
Para que a equipe pudesse trabalhar separadamente, foi essencial o uso de um método de controle de versões (CVS), assim como a criação de uma lista de discussão, que serviu como canal de comunicação entre os membros da equipe para avisar como estava o andamento do projeto e discutir sobre dúvidas que surgiram durante a implementação. Outro elemento de grande importância na nossa comunicação foi o telefone, permitindo que grande parte das decisões fosse feita "on-line", visualizando o código e discutindo.
A divisão inicial do trabalho previa o Gustavo trabalhando no módulo Canguru, a Maíra desenvolvendo a camada de persitência no banco de dados, que incluía tanto o Descriptor, quanto a camada de Proxy para o banco de dados e a Fernanda desenvolvendo a aplicação exemplo para o Canguru.
No andamento do projeto, encontramos dificuldades em desenvolver a aplicação cliente em paralelo com o desenvolvimento do Canguru em decorrência de alterações na interface do Canguru e do volume de desenvolvimento em outros módulos. Decidimos priorizar o desenvolvimento do arcabouço com testes automatizados utilizando o JUnit. A estrutura inicial para os testes, bem como toda a estrutura de comunicação (Wiki + Lista) e controle de fontes (CVS) foi desenvolvida pelo Gustavo.
Com a arquitetura mais madura, surgiu a definição dos três módulos existentes. O módulo Canguru, que inclui implementação da interface Set, introspecção, serialização e recuperação de referências, ficou a cargo do Gustavo. Já o módulo Proxy Database, que inclui a parte de comunicação com o banco de dados, a criação de tabelas e geração de comandos SQL para persistir, recuperar e buscar os objetos ficaram por conta da Maíra, com grande participação do Gustavo. Por sua vez, o módulo Descriptor, responsável pela conversão Banco-OO e pela definição das buscas, foi desenvolvido pela Maíra e pela Fernanda.
Na fase de pré-entrega do projeto, todos participaram executando e melhorando os testes de forma que todo o arcabouço fosse examinado. Assim que alguma falha era percebida, ela era corrigida independentemente que quem havia desenvolvido o código primeiramente. Aproveitamos para utilizar algumas técnicas de refatoração oferecidas pelo Eclipse para prover melhorias no código. O CVS e, principalmente, a comunicação por e-mails e telefone foram cruciais para a sincronização das alterações.
Prazos e andamento
O cronograma original de desenvolvimento era:
Julho: Estudo mais detalhado e modelagem do sistema.
Agosto: Introspecção, grafo de objetos, geração do banco, gravação de objetos.
Setembro: Busca, recuperação, proxy/memento e API.
Outubro: Ajustes, testes e aplicação exemplo.
Novembro: Apresentação e monografia.
Apesar dos esforços esse planejamento não foi respeitado. No início tínhamos feito uma modelagem vaga demais, sobravam muitas decisões para a etapa de implementação. Também gastamos muito tempo com protótipos do sistema de instrospecção.
Em setembro, utilizando o conhecimento que havíamos adquirido com a fase inicial do desenvolvimento, remodelamos o sistema de uma forma mais precisa e modularizada. Os benefícios foram imediatos: a divisão de tarefa, que antes era algo difícil, se tornou um processo natural, e as dúvidas, antes muito comuns durante o desenvolvimento, passaram a ser mais raras de de fácil resolução.
O desenvolvimento passou a ter um ritmo muito bom, porém já não tínhamos muito tempo e itens como a utilização de proxies e a aplicação exemplo, que faziam parte da proposta inicial, tiveram que ser deixados de lado.
Considerações finais
O resultado do projeto, o Canguru, agradou a toda a equipe, pois é uma ferramenta útil e de simples uso, que não exige configurações complicadas ou implementação de interfaces por parte do usuário, como era nosso objetivo inicial.
A intenção do grupo é continuar o seu desenvolvimento, aprimorando aquilo que já possuímos e incorporar novos recursos ao Canguru, tendo sempre em mente sua principal característica, que é a simplicidade. Alguns pontos que seriam interessantes no Canguru e que merecem ser estudados são:
- Permitir um auto-save configurável e segurança baseada em logs: hoje, em caso de uma pane no sistema cliente, todos os dados alterados desde a última chamada do método save são perdidos.
- Implementar outras Collections, dando mais flexibilidade ao desenvolvedor.
- Implementar novos modos de armazenamento: isso faria com que o Canguru pudesse salvar os dados em outros tipos de banco de dados, e não só o PostgreSQL, ou mesmo em XML.
- Armazenamento seletivo em memória: os objetos só seriam carregados em memória quando requisitados, não havendo a necessidade de manter todos os objetos em memória, como acontece hoje.
- Aprimorar o sistema de busca, permitindo a utilização de índices, busca por padrões, inserção de outros operadores lógicos (como OR e NOT) e outros operadores relacionais (como <, >, <=, >=);
Desafios e frustrações encontrados
No decorrer do projeto encontramos momentos de dificuldades, a maioria superada e outros viraram frustrações ou objetivos para a versão 2 do Canguru.
Tempo. Encontrar tempo para fazer o projeto foi sem dúvida a maior dificuldade que encontramos. Três fatores contribuíram para isso:
- Fizemos o projeto em grupo. Encontrar horário para reunir os três integrantes era algo difícil.
- Até Julho os três integrantes trabalhavam quase que em período integral.
- Durante o segundo semestre de 2003 cursei disciplinas que exigiam bastante tempo de dedicação.
Após os primeiros 4 meses o ritmo do desenvolvimento era muito baixo, estávamos bem atrasados em relação ao cronograma proposto. Percebemos que deveríamos minimizar a necessidade de atividades em grupo, passamos a trocar muita informação por e-mail e a fazer rápidas reuniões somente para discutir assuntos que considerávamos fundamentais e as tarefas foram divididas o máximo possível. Dessa forma conseguimos atingir um nível de produção satisfatório.
Em Julho deixei meu emprego, o que veio a contribuir em muito para a velocidade do desenvolvimento.
Apesar dos esforços algumas funcionalidades que gostaríamos de incluir na versão inicial do Canguru tiveram de ser deixadas a versão 2. O tempo foi ao mesmo tempo um desafio e uma frustração.
Recuperar os objetos sem quebrar as referências foi para mim o desafio mais motivante, passamos por diversos protótipos antes de chegar no modelo atual, pesquisamos bastante. Apesar de não termos resolvido totalmente o problema temos uma solução bem satisfatória para a maioria dos casos e que pode ser estendida para uma solução completa com um pouco mais de trabalho.
Disciplinas do BCC e o projeto
MAC 110 - Introdução à Computação,
MAC 122 - Princípios de Desenvolvimento de Algoritmos,
MAC 211 - Laboratório de Programação.
Essas disciplinas são as primeiras a colocar o aluno em contato com a programação, ensinando boas práticas de codificação,
comentários e indentação. São essenciais para que o aluno produza código bem organizado e comece a se preocupar com a eficiência
dos algoritimos produzidos. MAC 122 tem ainda o mérito de ter propiciado meu primeiro contato com java e com conceitos de programação
orientada a objetos.
MAC 323 - Estruturas de Dados.
Estrutura de dados é uma disciplina de muito grande importância para o curso e sem dúvida teve muita importância para o projeto,
ela me ensina a escolher e implementar estruturas que podem ser consideradas os blocos básicos de uma grande parte dos projetos em
computação. Em um projeto como o Canguru, que trabalha diretamente com persistência de dados, conhecer estruturas de dados é fundamental.
MAC 441 - Programação Orientada a Objetos.
Teve importância fundamental para o projeto uma vez que foi em MAC 441 que tive os primeiros contatos com modelagem estrutural e
de sistemas OO, técnicas de reuso, padrões e arcabouços. É uma pena que uma disciplina como essa não seja obrigatória no currículo do
Bacharelado em Ciência da Computação.
MAC 221 - Construção de Montadores,
MAC 211 - Laboratório de Programação.
Foram as primeiras disciplinas a exigir projetos maiores que os tradicionais Exercícios Programas. É inquestionável o quanto os
EPs contribuem para o aprimoramento das técnicas de desenvolvimento e programação, porém só quando trabalhamos com projetos maiores é
que aprendemos a gerenciar problemas como organização, estruturação, modularização e documentação de volume maior de código.
MAC 332 - Engenharia de Software.
É a única disciplina que abordou os processos de especificação, planejamento e testes de um projeto computacional, abordou ainda
diversos modelos de desenvolvimento. O Canguru se beneficiou principalmente do que aprendi sobre planejamento e testes.
MAC 426 - Sistemas de Bancos de Dados.
Como já foi mencionado, o Canguru possui hoje apenas um mecanismo de armazenamento e esse mecanismo utiliza intensamente sistemas
de banco de dados relacionais. MAC 426 é a primeira disciplina que colocou-me em contato com a utilização e o mecanismo de
funcionamento de sistemas de banco de dados, principalmente relacionais.
MAC 438 - Programação Concorrente.
O Projeto necessitou de tratamento de concorrência na API pública do Canguru, os conceitos e técnicas utilizadas foram aprendidas
no curso de programação concorrente.
MAC 328 - Algoritimos em Grafos.
O Canguru trata a coleção de objetos a ser persistida como um grafo dirigido onde, os objetos são os vértices e as referências as
arestas. Algoritimos em grafos são utilizados para percorrer essa coleção tratando os objetos.
MAC 338 - Análise de Algoritmos.
No projeto de um arcabouço, eficiência merece atenção extra pois, em geral tem-se como objetivo que ele seja utilizado pelo maior
número possível de desenvolvedores, e performance é um critério importante na escolha de um arcabouço, além disso o código poderá ser
utilizado em diversos tipos de aplicações distintos.
O trabalho em equipe
Gosto muito de trabalhar em equipe, acho que essa forma de trabalho traz muitos benefícios. Um dos mais importantes é ter com quem discutir a modelagem e também os detalhes de implementação, isso aconteceu o tempo todo durante o projeto. A única dificuldade que enfrentamos foi a divisão das atividades.
No inicio da fase de codificação, quando as tarefas ainda não estavam bem definidas, me senti monopolizando o desenvolvimento, os outros integrantes ficavam ociosos por não conseguirmos dividir os afazeres de forma adequada. Acabamos percebendo que o verdadeiro problema era na modelagem do Canguru, que estava muito vaga. Após rediscutirmos a arquitetura e definir um modelo mais aprofundado que o inicial conseguimos repartir o trabalho de forma mais ou menos equilibrada.
A maior parte da comunicação entre os integrantes da equipe se deu através de e-mail e aplicativos de mensagens instantâneas. Infelizmente tivemos poucas oportunidades de trabalharmos os três juntos. Eu esperava utilizar programação pareada para os trechos mais críticos do código, porém isso acabou não acontecendo.
O principal fator que dificultava o encontro da equipe eram os empregos, na etapa final do projeto a dedicação de um dos membros aos deveres profissionais era tão grande que não conseguíamos nos encontrar nem aos finais de semana, isso me incomodou muito.
Acho importante ressaltar que, apesar de termos nos encontrado pouco pessoalmente, o projeto correu muito bem por email e CVS, provando que essa é uma forma eficiente de trabalhar com times de desenvolvedores dispersos.
Conclusão
Esse projeto me trouxe bastante satisfação pelos seguintes motivos:
- Conseguimos nos coordenar, como equipe, apesar de quase toda a codificação ter sido feita individualmente.
- Aprendi bastante sobre técnicas de persistência e introspecção.
- E, acima de tudo o resultado final atingiu quase todos nossos objtivos iniciais.
Referências
[1] API Canguru (javadoc), api/index.html
[2] API Java 1.4.2 (javadoc), http://java.sun.com/j2se/1.4.2/docs/api/
[3] Documentação do PostgreSQL 7.3, http://www.postgres.org/docs/7.3/static/index.html
[4] Java Beans, http://java.sun.com/products/javabeans/
[5] Especificação do Java Beans, http://java.sun.com/products/javabeans/docs/spec.html
[6] MILNE, Philip e WALRATH, Kathy. Long-Term Persistence for JavaBeans
[7] JOHNSON, Mark. Make JavaBeans mobile and interoperable with XML
[8] Enterprise Java Beans, http://java.sun.com/products/ejb/
[9] Prevayler, http://www.prevayler.org/
[10] Hibernate, http://hibernate.sourceforge.net/
[11] JBoss, http://www.jboss.org/
[12] JMangler, http://javalab.cs.uni-bonn.de/research/jmangler/
[13] Javassist, http://www.csg.is.titech.ac.jp/~chiba/javassist/
[14] OGNL, http://ognl.org/
[15] JXPath, http://jakarta.apache.org/commons/jxpath/index.html
[16] JUnit, http://www.junit.org/
[17] CVS, http://www.cvshome.org/