MAC 499 - Trabalho de Formatura
Supervisionado
Bagging e
Boosting Aplicados ao Projeto de Operadores Morfológicos de Imagens
Autor: Jefferson Schoenfeld (jeffscho@linux.ime.usp.br)
N.o USP: 3669912
Orientadora: Profa. Dra. Nina S. T.
Hirata
Conteúdo
Introdução
O crescente aumento
da capacidade de processamento das máquinas ao longo das últimas décadas tem
permitido que a atividade de classificação de dados seja aplicada na solução de
um número cada vez maior de problemas práticos. Exemplos: Análise de
sequências de DNA, autenticação de pessoas via dados biométricos, análise
de imagens. Esse fato tem estimulado a
realização de pesquisas em áreas do conhecimento relacionadas ao problema
da classificação de dados.
Nosso trabalho foi motivado pelo resultado de
algumas dessas pesquisas, as quais mostram que através do uso de técnicas de
combinação de classificadores pode-se obter classificadores
com uma melhor taxa de acerto que a obtida individualmente com os classificadores utilizados na combinação.
Os resultados citados acima foram geralmente obtidos de forma empírica.
Portanto neste trabalho realizamos experimentos
visando verificar a eficiência da aplicação de duas técnicas de combinação
de classificadores conhecidas como Bagging e Boosting. Os dados
experimentais foram obtidos do contexto de projeto de operadores
de imagens. Para a realização dos experimentos foi utilizado o software
WEKA. Apresentaremos a seguir os fundamentos teóricos estudados que
possibilitaram a obtenção da compreensão necessária para a realização
dos experimentos, assim como a descrição e análise dos experimentos
realizados.
Fundamentos
Esta seção contém os conceitos básicos sobre aprendizado
supervisionado, combinação de classificadores e operadores morfológicos de imagens.
Parte1: Classificadores
Aprendizado
supervisionado
Antes de mostrarmos a definição formal do
problema de aprendizado supervisionado padrão é interessante
conhecermos as definições de alguns termos usuais na literarura da
área de aprendizado de máquina e que serão encontrados ao longo deste
trabalho.
- Um exemplo ou instância é um conjunto
de valores pertencentes a determinadas variáveis.
- Uma das variáveis em particular de um exemplo
é chamada de classe e as demais variáveis são chamadas de atributos
ou características. Essa divisão também pode ser feita como
variável dependente (classe) e variáveis independentes
(características).
- Um conjunto de dados é um conjunto de
exemplos.
- Um classificador é um mapeamento entre
os atributos de um exemplo e sua classe. Um classificador é gerado a partir de um conjunto de
dados chamado de conjunto de treinamento. Um conjunto de teste é
um conjunto de dados utilizado para avaliar a performance de um
classificador.
- Um programa de aprendizado é um programa de
computador que utiliza algum algoritmo de aprendizado que gera um
classificador ao receber como entrada um conjunto de treinamento.
- Na tarefa de aprendizado, assume-se que existe
uma função desconhecida ou verdadeira que faz o mapeamento entre
as variáveis independentes e a variável dependente. Geralmente não é
possível descobrir essa função a partir de um conjunto finito de dados.
Então o objetivo do programa de aprendizado é gerar um classificador que
por sua vez representa uma aproximação para essa função desconhecida.
O processo de construção de um classificador a partir de um conjunto de exemplos cujas
classes são conhecidas recebe o nome de aprendizado
supervisionado. Caso as classes não sejam conhecidas o algoritmo de
aprendizado deve identificar grupos no conjunto de dados e atribuir-lhes
classes, ou seja, as classes são inferidas do conjunto de dados. Nesse caso o
processo recebe o nome de aprendizado não-supervisionado.
Definição formal:
Considere um programa de aprendizado que recebe
como entrada um conjunto de treinamento L com M exemplos
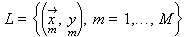
Os valores dos xm são tipicamente
vetores da forma <xi,1, xi,2, ..., xi,n>
cujos componentes são chamados de características de xi.
Os valores de ym
são tipicamente elementos de um conjunto discreto de classes {1,...,K}.
Assume-se que existe uma
função f tal que y = f(x) para todo (x,y).
A aplicação de um
programa de aprendizado em L gerá como saída um classificador f ' que é uma
hipótese com relação a função f. Dados novos valores x é
possível predizer o valor y correspondente através da aplicação da hipótese f '.
Como avaliar os classificadores
Os classificadores podem ser avaliados
segundo diversos aspectos como por exemplo tempo de aprendizado e tempo de classificação.
Porém em nosso trabalho estamos interessados em avaliar apenas a taxa de
acerto de um classificador.
Considere um conjunto de dados qualquer. Um
classificador prediz uma classe para cada instância. Se a classe predita é a
mesma que a classe da instância então ocorreu um sucesso, caso contrário
ocorreu um fracasso. A taxa de acerto de um classificador no conjunto de dados
então é dada pelo número de instâncias em que houve sucesso na predição
dividido pelo número total de instâncias.
A taxa de acerto no conjunto de treinamento não
é confiável como performance futura do classificador já que os dados desse
conjunto foram utilizados na construção do classificador. Normalmente
utiliza-se um conjunto independente do conjunto de treinamento chamado
conjunto de teste para se ter uma idéia da performance futura do
classificador. Espera-se que os dados de ambos os conjuntos sejam
representativos do problema em questão e no caso de termos uma grande
quantidade de dados disponível utiliza-se o seguinte método:
Obter conjuntos de
treinamento e teste tão grandes quanto possível, gerar o classificador,
medir sua taxa de acerto no conjunto de teste e construir um intervalo de
confiança.
A taxa de acerto de um único exemplo de um
conjunto de teste pode ser vista como um processo de Bernoulli com uma taxa de
acerto p desconhecida. Se o conjunto tem n exemplos, dos quais
S foram classificados com sucesso, então temos uma taxa de acerto
observada F = S / n. Com esses dados podemos construir um intervalo de
confiança para p.
Seja X uma variável aleatória de
Bernoulli com taxa de sucesso p. Então temos que E[X] = p e Var[X]
= p(1 - p).
No caso de um conjunto de teste com n exemplos, S
é uma variável aleatória com distribuição binomial ~ B(n, p). Logo
E[S] = np e Var[S] = np(1 - p).
A taxa de acerto
observada F também é uma variável aleatória e como sabemos sua relação com
S temos que E[F] = E[S] / n = p e Var[F] = Var[S] / n2
= p(1 - p) / n.
Para n suficientemente grande, F pode ser
aproximada para uma normal e assim temos que:
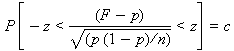
Consultando a tabela da normal padronizada e definindo o valor de z
para um certo nível de confiança temos como limites do intervalo de
confiança para p:
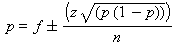
Resolvendo a equação do segundo grau chegamos a uma expressão para o intervalo de confiança da taxa de acerto
p:
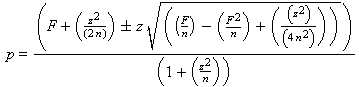
Este foi o método utilizado para avaliar os
classificadores em nosso trabalho, já que a quantidade de dados disponível
era suficientemente grande. Entretanto em muitas aplicaçoes a quantidade de
dados dísponivel é escassa. Nesse caso utiliza-se outro método para
avaliar os classificadores gerados, sendo que o mais empregado tem o nome de n-fold Cross-Validation.
n-fold Cross-Validation
Os exemplos são randomicamente divididos
em n partições. Separa-se uma das n partições para ser utilizada como
conjunto de teste enquanto as restantes são utilizadas como conjunto de
treinamento. Um classificador é gerado e a taxa de acerto no conjunto de
teste é calculada. O processo é repetido n vezes, de forma que cada uma das
n partições seja utilizada como conjunto de teste uma vez. A taxa de acerto
final é uma média da taxa de acerto calculada em cada partição quando
utilizada como conjunto de teste. Esse método é mais eficiente quando se
aplica uma técnica chamada estratificação que faz com que as partições
sejam geradas de tal forma que a distribuição das classes em cada partição
seja parecida com a distribuição das classes no conjunto de dados como um
todo. Na literatura recomenda-se a utilização dessa técnica para conjuntos
de dados escassos e, como obtemos uma média de uma variável aleatória com
distribuição desconhecida como resultado da taxa de acerto, para compararmos
a performance de dois classificadores devemos realizar testes de hipóteses.
Informações mais detalhadas são encontradas em [1].
Algoritmos de aprendizado
Utilizamos dois algoritmos
de aprendizado para geração de classificadores nos experimentos realizados:
Árvores de decisão e redes neurais.
Segue uma descrição de seus princípios básicos.
Árvores de decisão
Este algoritmo usa a estratégia de divisão e
conquista. Ele divide um problema complexo em sub-problemas e recursivamente
aplica a mesma estratégia para os sub-problemas. Por fim, as soluções dos
sub-problemas podem ser combinadas para gerar a solução do problema inicial.
Dado um conjunto de dados, inicialmente o
algoritmo seleciona um dos atributos para ser raiz da árvore. São
criadas ramificações da raiz baseadas nos valores desse atributo escolhido ou
em testes condicionais envolvendo esses valores. Isso provoca uma divisão do
conjunto de dados em sub-conjuntos, onde cada sub-conjunto possui apenas as
instâncias que satisfazem os valores, ou testes envolvendo os valores, do
atributo escolhido inicialmente. Em seguida o processo é repetido
recursivamente para cada ramificação. O critério de parada de
desenvolvimento de um ramo da árvore é quando todas as instâncias de um
determinado ramo possuem a mesma classificação, ou seja, uma mesma
classe. O algoritmo pode ser representado da seguinte forma:

Redes Neurais
O tipo de rede neural que foi utilizada em nosso
experimento é chamada de rede de múltiplas camadas. Cada camada é formada
pelas unidades básicas que são chamadas de Perceptrons ou neurônios
artificiais. Numa rede com múltiplas camadas os neurônios de uma camada
estão interligados com os neurônios da camada seguinte. Cada neurônio
possui um conjunto de entradas com pesos associados e uma saída que corresponde a aplicação de uma função ao somátoria das entradas ponderadas
pelo peso, essa função recebe o nome de função de ativação. A figura
seguinte ilustra as definições dadas acima:
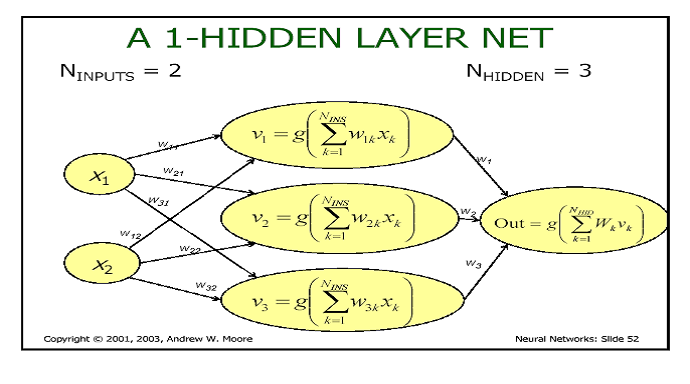
Dado um conjunto de treinamento, os atributos de
um exemplo servem como entrada da rede. Os valores calculados são propagados
de camada em camada até que a última camada produz um valor de saída. Como
sabemos qual a classe associada aos atributos da entrada, pois estamos lidando
com aprendizado supervisionado, temos uma função de erro que é
basicamente a diferença entre a saída esperada e a saída que efetivamente
foi produzida pela rede. O processo de aprendizado da rede consiste em ajustar
os pesos da rede de forma a minimizar essa função de erro.
A função de ativação utilizada é a sigmóide
:
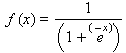
O processo de aprendizado ocorre segundo o
algoritmo de retro-propagação:
1. Inicializar todos os pesos
randomicamente com valores pequenos.
2. Selecionar um exemplo do conjunto de
treinamento (x, y) e calcular os valores de saída de cada neurônio,
utilizando esse exemplo como entrada.
3. Para cada neurônio da última camada,
calcular o seguinte valor que será utilizado no ajuste dos pesos:
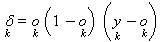 onde
ok é a saída produzida pelo neurônio k e yk é a
saída esperada no neurônio k.
onde
ok é a saída produzida pelo neurônio k e yk é a
saída esperada no neurônio k.
4. Para os neurônios das camadas
anteriores calcular os deltas por retro-propagação do erro usando:
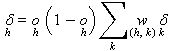 onde
oh é a saída produzida pelo neurônio h, wh,k é o
peso associado entre o neurônio h e os k neurônios da camada seguinte ao
qual está associado, e d
k é o delta calculado no passo 3 para os k neurônios da
camada seguinte ao qual o neurônio h está associado.
onde
oh é a saída produzida pelo neurônio h, wh,k é o
peso associado entre o neurônio h e os k neurônios da camada seguinte ao
qual está associado, e d
k é o delta calculado no passo 3 para os k neurônios da
camada seguinte ao qual o neurônio h está associado.
5. Atualizar os pesos através da seguinte
fórmula:
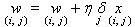
Onde a constante h
recebe o nome de taxa de aprendizado e os xi,j são as
entradas às quais os pesos estão associados.
6. Retornar para o passo 2 e repetir o
processo para um novo exemplo obtido do conjunto de treinamento até que algum
critério de parada seja observado. Esse critério pode ser um número
pré-definido de iterações ou um tempo de treinamento.
Mais informações são encontradas em [2].
Parte2: Combinação de classificadores
Idéia geral
O desenvolvimento de técnicas que combinam
diversos classificadores de algum modo com o objetivo de obter uma taxa de
acerto cada vez melhor é uma área de pesquisa ativa e diversos estudos
experimentais que avaliam a eficiência dessas técnicas têm sido produzidos.
Conforme demonstrado em [4], uma condição necessária e suficiente para que
um classificador formado pela combinação de diversos classificadores tenha
melhor taxa de acerto que seus membros é que os classificadores utilizados na
combinação sejam diversos entre si e tenham uma taxa de acerto superior a
50%. Dois classificadores são diversos entre si se cometem erros de
classificação em exemplos distintos de um conjunto de teste. Nesta parte do
trabalho mostraremos os conceitos gerais de duas técnicas bastante
empregadas: Bagging e Boosting.
Bagging
Vejamos o algoritmo de aplicação da
técnica Bagging:
Geração dos classificadores
Dado um conjunto de treinamento com n
instâncias.
Para cada uma das t iterações:
Criar um
novo conjunto de treinamento sorteando n instâncias do conjunto de
treinamento inicial com reposição.
Aplicar o
algoritmo de aprendizado para o conjunto de treinamento criado.
Armazenar o
classificador gerado.
Classificação
Para cada um dos t classificadores
armazenados:
Predizer a
classe de cada instância do conjunto de treinamento inicial.
Para cada instância do conjunto de treinamento
inicial retornar a classe que foi predita o maior número de vezes.
Logo a técnica consiste em criar novos conjuntos
de treinamento a partir de um conjunto inicial e para cada conjunto criado, gerar um
classificador aplicando um algoritmo de aprendizado, sendo que o algoritmo de
aprendizado deve ser o mesmo em todas iterações. O classificador final é
formado pela votação dos classificadores individuais criados, sendo que cada
classificador tem o mesmo peso na votação. Essa técnica tem apresentado
bons resultados quando o algoritmo de aprendizado utilizado é instável. Um
algoritmo de aprendizado é instável quando gera classificadores bastante
diversos ao ser aplicado a conjuntos de dados com pequenas diferenças entre
si.
Boosting
Vejamos o algoritmo de aplicação da
técnica Boosting:
Geração dos classificadores
Dado um conjunto de treinamento com n
instâncias, associar a cada instância um peso igual a 1 / n.
Para cada uma das t iterações:
Aplicar o
algoritmo de aprendizado para o conjunto de treinamento e armazenar o
classificador gerado.
Calcular a
taxa de erro e do classificador no conjunto de treinamento e armazenar
esse valor.
Se e
= 0 ou e >= 0.5:
Finalizar a geração de classificadores.
Para
cada instância no conjunto de treinamento:
Se a instância foi classificada corretamente pelo classificador:
Multiplicar o peso da instância por e / (1 - e).
Normalizar
o peso de todas instâncias.
Classificação
Inicializar todas classes com peso igual a zero
Para cada um dos t (ou menos)
classificadores:
Adicionar -log(e
/ (1 - e)) ao peso da classe predita pelo classificador.
Para cada instância do conjunto de treinamento
inicial retornar a classe que possui peso com maior valor.
As semelhanças com Bagging são que na técnica
Boosting os classificadores também são gerados através de modificações no
conjunto de dados inicial e o classificador final é formado por
votação dos classificadores indivuduais, porém o modo como isso é feito é
diferente.
Em Boosting, partimos de um conjunto de dados
inicial e geramos um classificador. Um novo conjunto de dados é criado
de acordo com o resultado do classificador. As instâncias que são
classificadas corretamente pelo classificador têm seu peso reduzido e as
instâncias classificadas incorretamente têm seu peso aumentado. O algoritmo
é sensível aos pesos dos exemplos contidos no conjunto de dados e dessa
forma é "forçado" a classificar de forma correta os exemplos com
maior peso, pois a próxima iteração utilizará o conjunto de dados com peso
modificado para gerar o novo classificador. Esse processo é repetido um certo número de iterações gerando
alguns classificadores. O classificador final é formado por votação dos
classificadores individuais, porém o voto de cada classificador possui um
peso que está diretamente relacionado ao desempenho individual do
classificador. Percebemos que com essa técnica também geramos
classificadores que são complementares entre si, pois cada classificador
tende a não cometer erros nas instâncias em que outros classificadores
cometeram erro, o que faz com que essa técnica também seja eficiente para
algoritmos instáveis.
Parte 3: Operadores morfológicos de imagens
Definição e projeto
Imagens discretas monocromáticas podem ser
definidas por funções do tipo f: Z2 ®
K = {0,1,...,k}, onde Z2 é o domínio da imagem e K
representa o conjunto de possíveis tons de cinza numa imagem. Imagens
binárias são casos particulares onde K = {0,1}.
Operadores de imagens são funções que mapeiam
imagens em imagens. Se denotarmos o conjunto de todas as imagens definidas em
E = Z2 por KE, então um operador de imagens é um
mapeamento da forma Y:KE
®
KE .
Existe uma classe de operadores morfológicos de
imagens que são invariantes a translação e localmente definidos por uma
janela W Í
Z2, chamados de W-operadores. Podemos dizer que para esse
tipo de operador o valor da imagem transformada Y(S)
em qualquer ponto x depende apenas de uma pequena vizinhança (restrita a W)
na imagem de entrada S em torno desse ponto. Nesse caso o mapeamento Y:{0,1}K
®
{0,1} pode ser modelado como uma função booleana em |W| (tamanho de W
em pontos), associando-se uma variável a cada ponto da janela.
Uma possível abordagem para o projeto de
operadores consiste na utilização de técnicas de aprendizado computacional:
pares de imagens entrada-saída são utilizados como dados de treinamento para
inferir um operador que mapeia a imagem de entrada para a respectiva imagem
saída. Se nos restringirmos ao contexto de imagens binárias e W-operadores,
o problema pode ser reduzido ao problema de aprendizado de uma função
booleana e, portanto, técnicas clássicas de reconhecimento de padrões e
classificação podem ser empregadas.
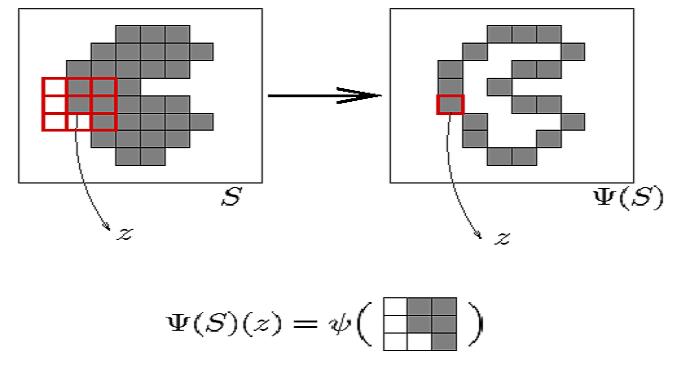
Os dados de treinamento são obtidos
percorrendo-se as imagens de entrada com a janela W e, em cada ponto,
coletando-se o padrão observado sob a janela (o objeto a ser classificado) e
o valor no mesmo ponto na imagem de saída (a correspondente classe), conforme
ilustrado na figura abaixo:
Descrição e análise dos experimentos
O objetivo principal foi verificar se
existem indícios experimentais significativos de que o uso de técnicas de
combinação de classificadores podem melhorar a taxa de acerto quando
aplicadas aos algoritmos de árvores de decisão e redes neurais usando dados
experimentais obtidos do contexto de projeto de operadores
de imagens.
1. Obtenção dos dados experimentais
Para projetar um operador usando técnicas de treinamento, pares de
imagens entrada-saída são utilizados para a obtenção dos
exemplos de treinamento. Os exemplos de treinamento são padrões
observados na imagem de entrada através de uma janela W juntamente com o valor correspondente
(geralmente o pixel sob o ponto central da janela) na imagem de saída,
conforme foi explicado na seção: Operadores morfológicos de imagens.
Os exemplos de treinamento e teste dos experimentos
foram obtidos utilizando-se um software desenvolvido pelo grupo de
Visão Computacional do IME-USP. Este software é, por enquanto,
restrito ao uso do grupo. Uma documentacão de uma versão inicial pode ser encontrada em
[10]. Atualmente ele roda junto ao ambiente Khoros. O resultado coletado é
expresso através de um arquivo com extensão xpl, que possui como
informações basicamente o tamanho da janela utilizada na coleta dos dados,
os padrões observados e o número de vezes que cada classe foi associada ao
padrão, ao se percorrer a imagem de entrada. Como utilizamos apenas imagens
binárias, os valores da classe pertencem ao conjunto K = {0,1}. Lembrando que
os padrões observados são os valores observados em cada pixel da janela
utilizada na coleta dos dados. Esse conjunto de valores corresponde aos
atributos de um exemplo.
2.Geração dos classificadores
Obtidos os dados experimentais, o passo seguinte
foi a aplicação dos algoritmos de aprendizado para geração dos
classificadores. Utilizamos para essa tarefa o software WEKA
(www.cs.waikato.ac.nz/ml/weka), que possui,
implementados na linguagem Java, os principais algoritmos de aprendizado de
máquina incluindo técnicas de combinação de classificadores. O software
fornece uma interface gráfica bastante amigável, porém para nossos
experimentos foi necessário criar um script para fazer chamadas ao software
usando a interface de linha de comando pois nesse caso temos disponíveis
alguns parâmetros úteis que não estão disponíveis via interface gráfica,
além do consumo de memória ser menor.
O WEKA requer que os dados de entrada estejam num
formato próprio com extensão arff. Para essa tarefa criamos o arquivo
FormatXPL2ARFF.java. O nome do script criado é build.xml e é lido pelo
programa ANT(http://ant.apache.org). O script tem uma funcionalidade parecida com um makefile onde
podemos definir vários "targets". Em anexo enviamos o arquivo Weka.tar.gz que possui um arquivo README contendo uma descrição mais
detalhada sobre o ambiente criado para execução dos experimentos assim como
os dados de entrada, o script build.xml, os dados de saída e as instruções
necessárias para reproduzir os experimentos ou criar novos. Os dados de
saída são arquivos contendo informações sobre os classificadores. O dado
de interesse para nosso trabalho foi a taxa de acerto no conjunto de teste.
3.Visualização e análise dos resultados
(avaliação dos classificadores)
Em geral, deseja-se projetar (encontrar) operadores
de imagens que realizam processamentos desejados tais como filtragem de
ruído, extração de objetos de interesse, reconhecimento de certos tipos de
textura, entre outros.
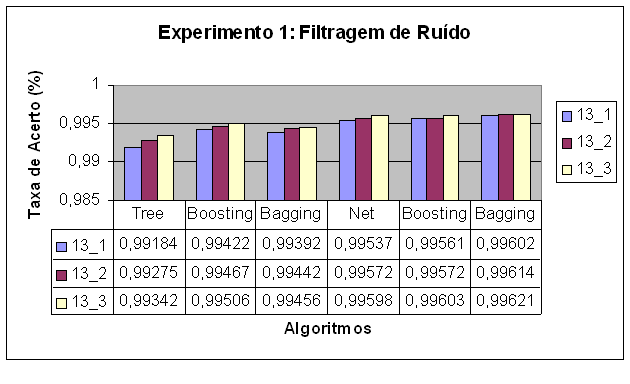
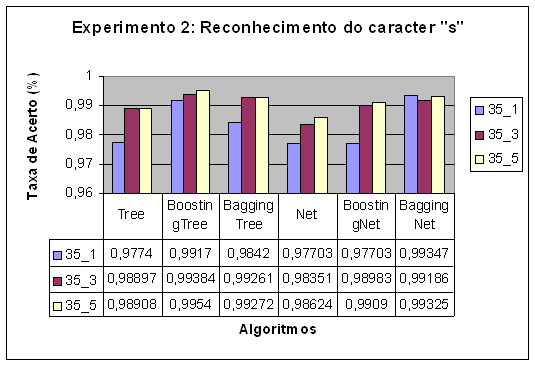
Em cada experimento geramos um classificador, de
acordo com a ordem da figura acima, para árvores de decisão, Boosting
e Bagging baseados em árvores de decisão, redes neurais e Boosting e Bagging
baseados em redes neurais. Na figura temos o resultado de taxa de acerto
observada experimentalmente em cada um dos casos. No arquivo Weka.tar.gz
incluímos o arquivo IC.doc que contém os intervalos de confiança calculados
para cada caso usando o método descrito na seção: Como avaliar os
classificadores. Os números mostrados na legenda da figura significam o
tamanho da janela utilizada na coleta de dados e o número de pares de imagens
entrada-saída das quais os dados de treinamento foram coletados.
Analisando os intervalos de confiança para o
experimento 1 podemos afirmar que as técnicas de Bagging e Boosting melhoram
o desempenho do classificador quando aplicadas a árvores de decisão, porém
para redes neurais essa melhora não foi significativa. Outra análise que
pode ser feita é com relação ao número de imagens entrada-saída
utilizadas no treinamento. Quanto mais pares utilizados no treinamento, maior
o número de exemplos no conjunto de treinamento e portanto espera-se obter um
classificador melhor. Esse efeito foi observado no experimento de forma mais
significativa para os casos onde foi utilizado o algoritmo de árvores de
decisão.
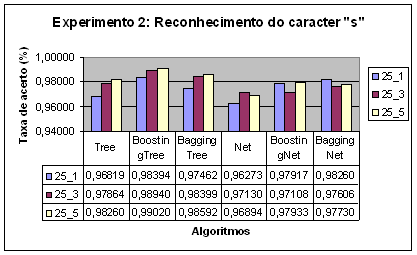
No experimento 2 podemos verificar que Boosting e
Bagging melhoram a taxa de acerto para ambos algoritmos, mas Boosting
apresentou um melhor desempenho para árvores de decisão, enquanto Bagging
apresentou melhor desempenho para redes neurais. A melhora com o aumento
de pares de imagens entrada-saída ficou mais evidente para o caso de árvores
de decisão.
Neste experimento apenas alteramos o tamanho da
janela utlizada para coletar os dados, isso faz com que os exemplos tenham
mais atributos. Nesse caso o aumento da quantidade de atributos fez com que os
classificadores gerados apresentassem uma taxa de acerto maior. O aumento do
número de atributos pode melhorar a taxa de acerto dos classificadores mas
isso nem sempre é verdadeiro como é demonstrado em [5].

Neste experimento ambas as técnicas de
combinação foram eficientes sendo que para redes neurais a combinação
provocou uma melhora mais significativa na taxa de acerto. Neste experimento o
aumento do número de exemplos no conjunto de treinamento não provocou uma
melhora na taxa de acerto.
Com base nos experimentos realizados podemos
concluir que a utilização das técnicas de combinação Bagging e Boosting
realmente provocaram uma melhora na taxa de acerto dentro do contexto de
operadores morfológicos de imagens. Esse resultado era esperado pois os
algoritmos de aprendizado utilizados, Árvores de decisão e redes neurais,
são algoritmos instáveis.
Experiência pessoal
Gostaria de expressar minha opinião sobre
o curso do BCC como um todo ao invés de falar sobre disciplinas
indivudualmente. Como pontos positivos do curso eu destacaria o currículo que
é bem estruturado e o corpo docente que é de ótimo nível. Tenho
convicção que essa ênfase dada a formação acadêmica prepara muito bem os
alunos para ingressar no mercado de trabalho porque tenho verificado que as
grandes empresas não procuram pessoas com experiência prática e sim pessoas
com boa formação acadêmica. Aliás minha frustração ao longo do curso tem
sido não ter condições de me dedicar em tempo integral, abrindo mão, de
certa forma, dessa oportunidade que o BCC oferece de se adquirir uma excelente
base teórica.
Com relação ao trabalho de formatura, os maiores
desafios foram decorrentes justamente da falta de tempo, porém acredito que
essa matéria é muito importante porque permite que nós alunos tenhamos um
contato mais direto e por mais tempo com os professores orientadores e essa
experiência propicia um amadurecimento intelectual.
Tenho a intenção de aprofundar esse conhecimento
que adquiri ao realizar o trabalho e acredito que o próximo passo é realizar
experimentos com imagens tons de cinza já que no trabalho atual fizemos
experimentos apenas com imagens binárias.
Agradecimentos
Quero agradecer minha orientadora,
professora Nina S. T. Hirata, por toda sua boa vontade e cooperação.
Referências
[1] Ian H. Witten and Eibe Frank
(2005) "Data Mining: Practical machine learning tools and
techniques", 2nd Edition, Morgan Kaufmann, San Francisco, 2005.
[2] Patterson, Dan W. Artificial Neural
Networks. Prentice Hall, 1995.
[3] Leo Breiman (1996). "Bagging
predictors". Machine Learning, 24(2):123-140.
[4] Dietterich, T. G. (2000). Ensemble Methods
in Machine Learning. In J. Kittler and F. Roli (Ed.) First
International Workshop on Multiple Classifier Systems, Lecture Notes in
Computer Science (pp. 1-15). New York: Springer Verlag
[5] A. K. Jain, R. P. W. Duin, J. Mao. Statistical
Pattern Recognition: A Review. IEEE Transactions on Pattern Analysis and
Machine Intelligence, Vol. 22, No. 1, Jan. 2000
[6] E. Bauer, R. Kohavi. An empirical comparison
of voting classification algorithms: Bagging, Boosting and Variants, Machine
Learning, vol. 36, 1999, 105--142.
[7] Robert P. W. Duin, David M. J. Tax: Experiments
with Classifier Combining Rules. Multiple Classifier Sustem 2000: 16-29
[8] E Alpaydin (1998) " Techniques for
Combining Multiple Learners," Engineering of Intelligent Systems
EIS'98, Teneriffe, Spain, February 1998
[9] Gama, J. M. P. "Combining Classification
Algorithms", Tese de Doutorado, Faculdade de Ciências da Universidade do Porto, Departamento de
Ciências de Computadores, 1999.
[10]
N. S. Tomita. Programação Automatica de Máquinas Morfológicas Binárias baseada em Aprendizado PAC.
Dissertação de mestrado, IME-USP,
1996.